PDF 문서 기반 Q&A 시스템 구축: LlamaIndex, ChromaDB, Ollama 활용 2부
오전에 올린 포스팅의 2부 마지막부입니다.
terminal 에서 질의를 한다는 것은 어찌보면 사용자측면에서는 좋은 것이 아니라 이 부분도 어떻게 할지 고민하다가 역시나 AI와 같이 협업을 통해서 성과물을 만들어 보았습니다.
Streamlit으로 Q&A 인터페이스 구축
이 UI 는 인덱스를 로드하고 mistral 모델로 한국어 답변을 하는 것을 만들어 본 소스입니다.
from llama_index.core import StorageContext, load_index_from_storage
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.llms.ollama import Ollama
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.core.prompts import PromptTemplate
import chromadb
import streamlit as st
import os
CHROMA_DIR = "./chroma_index"
COLLECTION_NAME = "my_index"
def load_index():
embed_model = OllamaEmbedding(model_name="nomic-embed-text")
chroma_client = chromadb.HttpClient(host="localhost", port=8000)
chroma_collection = chroma_client.get_or_create_collection(
name=COLLECTION_NAME, metadata={"hnsw:space": "cosine"}
)
chroma_store = ChromaVectorStore(chroma_collection=chroma_collection, chroma_client=chroma_client)
storage_context = StorageContext.from_defaults(vector_store=chroma_store, persist_dir=CHROMA_DIR)
index = load_index_from_storage(storage_context, embed_model=embed_model)
return index
st.set_page_config(page_title="📖 PDF 문서 기반 Q&A 시스템")
st.title("📖 PDF 문서 기반 Q&A")
st.markdown("🤖 PDF 내용을 바탕으로 질문에 답변합니다.")
question = st.text_input("질문을 입력하세요:", placeholder="예: 부자가 되는 방법")
if question:
index = load_index()
if index:
qa_prompt = PromptTemplate(
"질문: {query_str}\n컨텍스트: {context_str}\n답변: 한국어로만 답변해 주세요."
)
query_engine = index.as_query_engine(
llm=Ollama(model="mistral"), text_qa_template=qa_prompt
)
with st.spinner("🔍 답변 생성 중..."):
response = query_engine.query(question)
st.markdown("### 🤖 답변")
st.success(response.response)이 소스는
1. ./chroma_index에서 인덱스 로드
2. 한국어로 답변 시키도록 프롬프트 적용
=> PromptTemplate 한국어로만 답변해주세요 라고 해야 한국어로 나와요
아니면 영어로 나오니 주의하세요 <- 저도 사실 이 부분이 제일 이해가 안되는 부분
3. Streamlit 웹 에서 질문과 답변 표시
실행 방법
uv run streamlit run query_index.py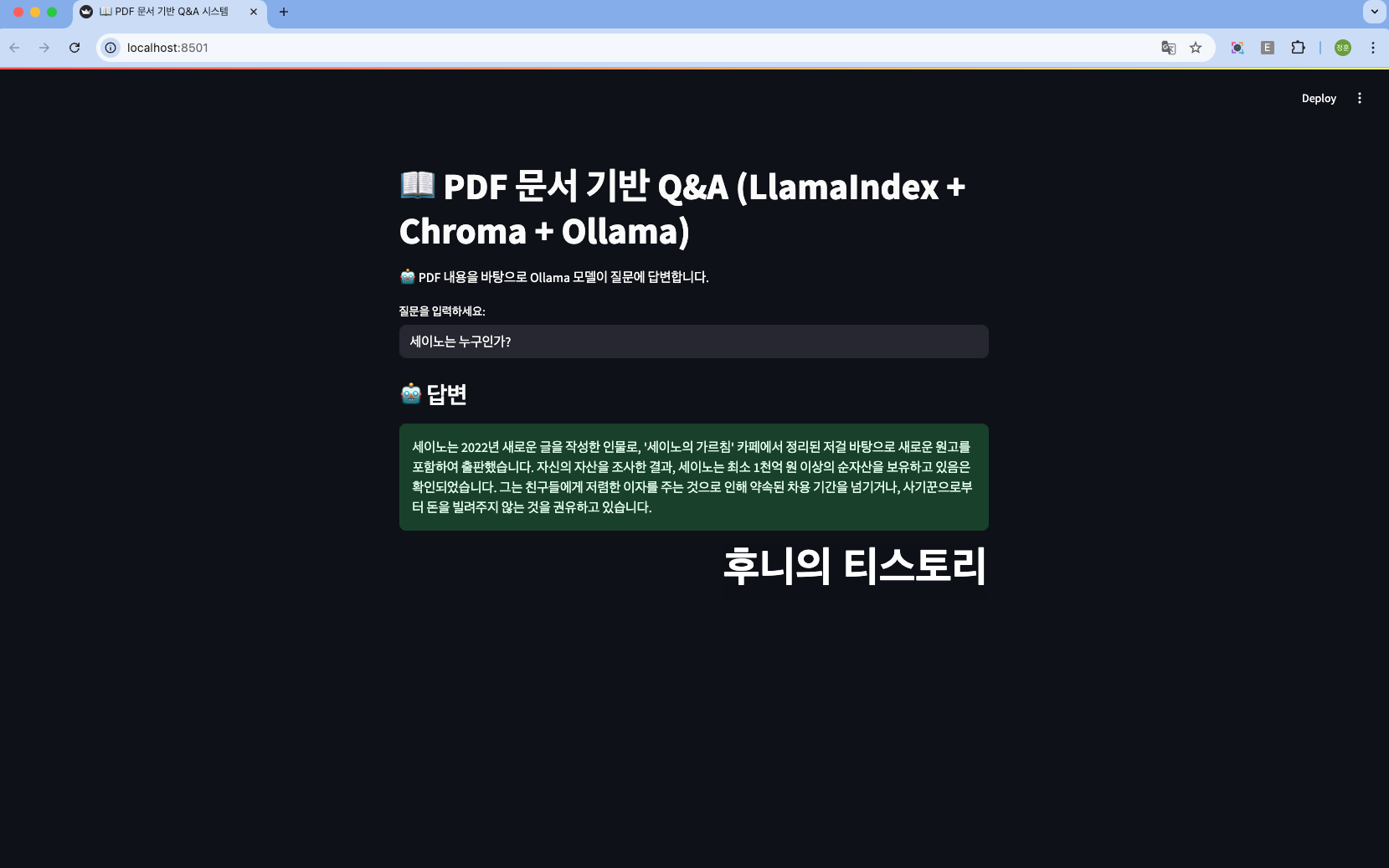
저는 이번 프로젝트에 사용한 pdf 파일은 세이노의 가르침 을 사용했습니다.
링크 주소는 아래와 같습니다.
https://blog.naver.com/dayonepress/223515971889
📚세이노의 가르침-무료 전자책과 오디오북 안내 (2025. 04. 23 update)
"세이노의 가르침-피보다 진하게 살아라" 데이원 운영 공식 블로그와 카페 ‘세이노의 가르침-피...
blog.naver.com
겪은 문제와 해결법
1. 인덱스로드 실패 : persist_dir 를 지정하지 않아 에러 발생
StorageContext.from_defaults(persist_dir=CHROMA_DIR) 로 해결
2. 영어로 답변 문제 : PromptTemplate 에 한국어로 답변 지시 추가
3. ChromaDB 연결 문제 : ./chroma_index 초기화 및 서버 재시작
chroma run --path ./chroma_index4. ChromaDB 가 구동중인지 확인 방법
http://localhost:8000/api/v1/heartbeat
이렇게 해서 작은 토이프로젝트를 하루만에 끝냈습니다.
역시 이번 기회에 AI 활용하는 것이 얼마나 중요한지 그리고 제가 만약에 혼자 했다면 이것은 한 1주 이상은 걸릴것 같았는데라는 생각이 들더군요.
4. 팁
디버깅: 스크립트에 logging.basicConfig(level=logging.DEBUG) 추가
회고
이 프로젝트를 통해서 AI 와 벡터 데이터베이스에 대해서 약간에 대한 감을 가지게 되었답니다. LlamaIndex 를 이용해서 PDF 인덱싱, ChromaDB 에 저장하며 Ollama Mistral 모델로 질문에 답변하는 시스템 구축은 정말 좋은 경험이고 앞으로 나아갈 수 있는 한걸음이었습니다.
즐거운 코딩되세요.
